ALBERT: A Lite BERT For Self-Supervised Learning of Language Representations
Motivation
A research direction that I’ve spent some time exploring recently is model compression; more specifically, techniques for compressing large embeddings. While the focus is on techniques that generalize to arbitrary NN model architectures, I have found myself spending a large portion of my time working on various variants of BERT. This is due to the fact that many product teams within and outside of Google are quickly moving to incorporate BERT into their NLU tasks in their problem domain, and finding out that it’s extremely expensive to productionize these models due to their size (both RAM required to serve them and computational resources and latency in doing real-time inference with them).
A few of the ideas my group has tinkered with are in the area of using various dimensionality reduction techniques and matrix decomposition to reduce the size of the embedding matrix - this is closely related to one of the two main contributions of the ALBERT paper and thus I decided to do a close review of their work.
Overview
This paper looks to make BERT more production-friendly, by reducing the amount of training time required and the over-all size of the network (required RAM at training and serving time). Their contributions are two-fold: two parameter-reduction techniques and a self-supervised loss that focuses on modeling inter-sentence coherence. They establish new state-of-the-art results on GLUE, RACE, and SQuAD benchmarks while dramatically reducing the size of the model.
Introduction
- Full network pre-training has led to a series of breakthroughs in language representation learning but require large networks.
- Claim that while in the BERT paper, Devlin et al. argue that larger hidden size, more hidden lyaers and more attention heads always leads to better performance, they stop at a hidden size of 1024. They show that if this argument were followed and the model were scaled up to a hidden size of 2048, it leads to model degradation (though they don’t talk much about how much effort went into optimization of BERT-xlarge relative to BERT-large for the task).
- The existing work mostly look at model parallelization and clever memory management to address memory limitation issues, but not much about the communication overhead (training) and model degradation (problem described in the previous bullet)
- Parameter reduction technique #1: factorized embedding parameterization - separate the embedding matrix so that the size of the embedding vocabulary is independent from that of the hidden layer.
- #2: cross-layer parameter sharing so that the # of parameters doesn’t grow with the depth of the network.
- Another contribution is the introduction of a self-supervised loss for sentence-order prediction (SOP) which addresses some problems with the next-sentence prediction loss of the original BERT.
Related Work
Scaling up representation learning for NL
- Chen et al’s method for checkpointing gradients to reduce the memory requirement to be sublinear at the cost of an extra forward pass.
- Gomez et al’s method of recreating each layer’s activations from the next layer so that intermediate activations don’t need to be stored in memory.
- Makes the point that both methods trade-off speed for memory consumption and that their method achieves both.
Cross-layer parameter sharing
- Sharing params across layers was explored with Transformer architecture but usually in the context of standard encoder-decoder models rather than the pretraining/finetuning setting.
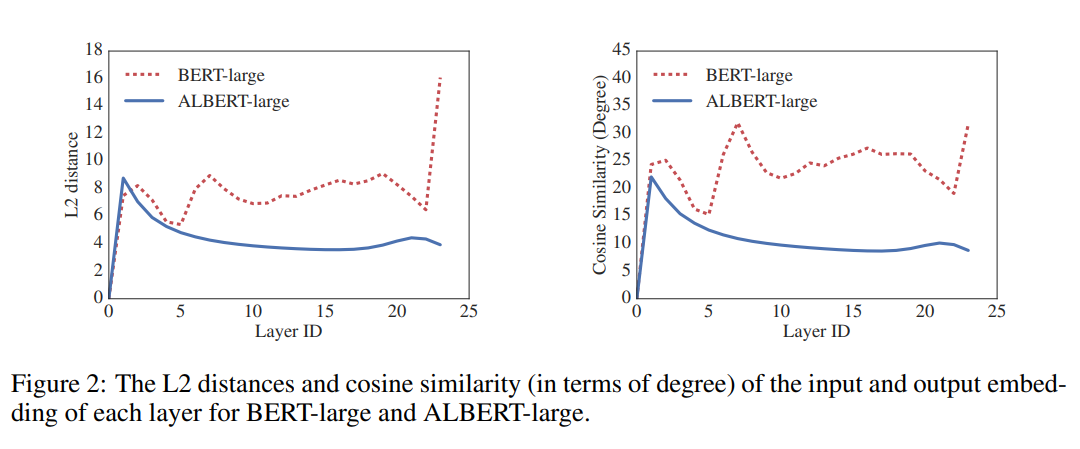
- They make a point about their embeddings oscillating rather than converging (opposing the observations of Bai et al’s DQE model in which the input embedding and the output embedding of a certain layer converge) which I don’t fully follow.. Hoping that it’s clarified later in the paper.
Sentence Ordering Objectives
Most other objectives that use similar notions of inter-sentence coherence use sentences as atoms whereas in ALBERT, the loss is defined on textual segments rather than sentences. They claim that SOP is both a more challenging problem and more relevant to certain downstream tasks, without citing any examples or evidence.
Elements of ALBERT
Factorized embedding parameterization
Key observation is that from a modeling perspective, WordPiece embeddings (and friends) learn context-independent representations, whereas the hidden-layer embeddings are meant to learn context-dependent representations of the vocabulary elements. This leads us to believe that the size of the hidden-layer embedding, \(H\), must be much greater than that of the WordPiece embedding (\(E\)).
Instead of projecting one-hot encoded vectors directly into the hidden space of \(H\), they first project them into a lower-dimensional embedding space of size \(E\) and then project it to the hidden space. By using this decomposition, they reduce the embedding parameters from \(O(V \times H)\) to \(O(V \times E + E \times H)\), which is significant because presumably \(H \gg E\) - it’s worth noting that the former matrix would be extremely sparsely updated during training, which is another problem that their work avoids.
They also mention that because they use WordPiece embeddings, which are somewhat evenly distributed across documents, they opt to use the same \(E\) for all word pieces - a future optimization could be varying the size of the space in which various wordpieces are embedded in to even further save space - though that is bounded by \(O(V \times E)\) which may not be significant when compared to \(O(E \times H)\).
Cross-layer parameter sharing
By default, ALBERT shares all parameters across layers (both for feed-forward network as well as the attention heads). By showing that in their setup, the transitions from layer to layer are much smoother those for BERT, they assert that weight-sharing has an effect on stabilizing network parameters. What is note-worthy is that unlike the DQE network mentioned in related work, neither cosine similarity nor L2 distance drop to 0 after 24 layers, showing that the solution space for ALBERT parameters is likely different than the one found by DQE.
Inter-sentence coherence loss
In addition to masked language modeling loss, BERT uses the next-sentence prediction loss, derived from and objective to improve performance on natural language inference and reasoning about the relationship between sentence pairs.
In BERT, positive examples and negative examples (sampled with equal probability) were created by taking consecutive segments from training corpus for the former and pairing segments from different documents for the latter.
They claim that NSP’s ineffectiveness (argued by other papers) is its lack of difficulty as a task, as compared to MLM, conflating topic prediction and coherence prediction in a single task. This is due to the fact that negative examples area not only misaligned from a coherence perspective (2 unrelated sentences), but also from a topic perspective (2 unrelated documents). They do a good job supporting this claim in their experimental results by showing that in fact, NSP cannot solve the SOP task at all (compared to random).
Experimental Results
Setup
They follow the BERT setup fairly closely, using the BookCorpus and English Wikipedia for pretraining baseline models. All text si formatted as “[CLS] \(x_1\) [SEP] \(x_2\) [SEP]” with \(x_1 = x_{1,1},x_{1,2}...\) with the maximum input length set to 512, randomly generating input sequences shorter than 512 with a probability of 10%. They use the SentencePiece tokenizer (which has a vocabulary of 30,000).
MLM target masks are generated via n-gram masking with length \(n\) (capped at 3) given by:
\[p(n) = \frac{1/n}{\sum_{k=1}^N{1/k}}\]Other hyperparams include batch size of 4096, LAMB optimizer, learning rate of 0.00176 (taken directly from existing work that Yang You did late 2019 during his internship at Brain), trained for 125,000 steps on 64-1024 Cloud TPU V3.
Evaluation
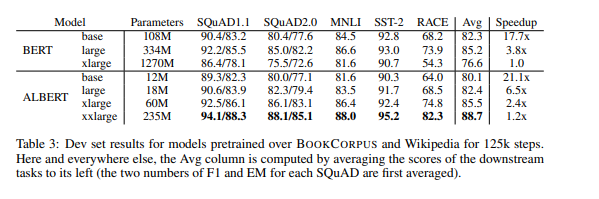
One somewhat unsubstantiated claim that they make is that because their version of BERT-xlarge (1270M parameters, compared to BERT’s 334M) does poorly in downstream tasks, that models the size of BERT-xlarge are more difficult to train than those that have smaller parameters sizes. First, this is almost true by tautological since as we increase the parameter size, there are more degrees of freedom and thus more energy has to be expanded to find the right configuration of parameters that allow the model to learn to solve the task. What they probably want to argue is that for BERT’s architecture, BERT-large is the optimal size, precluding the notion that we can improve the quality of the model just by increasing the size of the model.
I assert that this claim is unsubstantiated since they do not discuss how they arrived at the configuration or their hyper-parameter tuning regime, which they would need in order to support the claim that increasing the size of the BERT-large is not conducive to a good quality to cost trade-off.
They also show that ALBERT models have higher data throughput compared to their corresponding BERT models, which is self-explanatory given the fewer parameters and less communication. One surprising bit is that even though they discover that the all-shared cross-layer parameter sharing strategy hurts performance under both embedding sizes experimented (768 and 128), they choose it as the default choice. They mention that the FFN-layer parameter sharing is the cause of the performance drop so it is not obvious why they don’t elect to only share attention parameters.
The overall results of various formulations of the model are demonstrated below.
Abalation Experiments
Next, they try to isolate the individual effects of the important design decisions made.
Factorized Embedding Parameterization
The change the size of the embedding vocabulary \(E\) and test the results both with the default all-shared-parameters set-up for ALBERT as well as the original BERT-style set-up where no parameters across layers are shared, finding that in the non-shared condition, larger embedding sizes give slightly better performance. Under the all-shared condition, an embedding of size 128 appears to be the best.
Cross-Layer Parameter Sharing
There are a few configurations here, all tested with 2 different embedding sizes of \(E=128\) and \(E=768\):
- All-shared strategy (ALBERT-style)
- Not-shared strategy (BERT-style)
- Intermediate strategy 1 (only attention)
- Intermediate strategy 2 (only FFN)
All-shared strategy seems to hurt performance in both cases (more with larger embedding), most of the drop appearing to be caused by FFN-layer param sharing. In general, we can divide the \(L\) layers into \(N\) groups of size \(M\), with each group sharing their parameters. Experiments show that the smaller the group size \(M\) the better the performance. Howver, this also dramatically increases the number of overall parameters (12M vs. 89M all-shared vs. not-shared at \(E=128\)) so the all-shared strategy was chosen as the default.
Sentence Order Prediction (SOP)
This is an interesting study. Below we compare the performance of the model, trained with NSP (ALBERT-style), SOP(BERT-style) and none (XLNet- and RoBERTa-style):
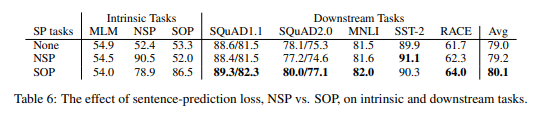
What is of interest is that NSP brings no discriminative power to the SOP task, while SOP solves NSP fairly well (78.9% accuracy).
Effect of Network Size and Training Time
In the last two sections, they discuss increasing the # of layers, width of layers (hidden size) and training time.
They find that diminishing marginal returns start to dominate at \(L=24\), and \(H=4096\). They then control the training time (as opposed the data throughput, i.e. the number of training steps) and find that after training for roughly the same amount of time, ALBERt-xxlarge does significantly better than BERT-large on all tasks.
They then establish that a very wide ALBERT model (24 layers) with all-shared strategy does not need to be deeper than 12 layers (which makes sense.. since the parameters are shared, there isn’t much expressiveness added with the model becoming deeper).
More Training Data and Dropout
By using data outside of the BookCorpus and Wikipedia datasets, they show that performance can be dramatically improved (except for the SQuAD task, which is Wikipedia-based where the out-of-domain training material expectedly hurts performance). They then show that using these augmentations to the training data, ALBERT significantly outperforms state-of-the-art for all three benchmarks.
Discussion
While ALBERT-xxlarge has fewer parameters than BERT-large, it is computationally more expensive due to its larger structure. A few next steps could be leveraging sparse attention, block attention or perhaps increasing the representation power by hard example mining, and more efficient language modeling training. While SOP seems to be much more useful than NSP, there is reason to believe a better self-supervised learning task that teaches the model more about the inter-sentence structure of the training material can create additional representation power for the resulting model.